이번에 리뷰할 논문은 Mobilnet이라는 논문입니다
이전 읽어 보았던 논문들이 속도와 정확도 향상에 중점을 둔 모델이었다면
해당 모델은 기존보다 정확도가 약간 떨어지더라도
robotics , self-driving 등에 사용되는 소형 임베디드 기기에서도 사용이 가능하도록
최대한 연산량을 줄여 효율적으로 만든 모델입니다
해당 논문의 주요 기술로는 depth-wise separable convolution 이 주요하며
채널수와 해상도를 조정하기 위하여 width multiplier와 rewolution multiplier이라는 하이퍼 파라미터를 사용합니다
해당 논문의 거의 대부분의 내용이 이 depth-wise separable convolution입니다
(이후 설명 중 입 출력의 size를 같게 하기 위하여 padding하는 과정은 생략하겠습니다)
기존의 convolution을 예로 들자면
만일 input이 Df*Df*M이 존재한다 가정하고 filter를 Dk*Dk로 사용하여
출력으로 입력과 해상도가 같고 채널수는 다른 Df*Df*N의 출력을 가지고 싶다면
필요 필터는 Dk*Dk*M의 필터를 N개 사용해야 할 것입니다

이렇게 되면 총 연산량은 Dk*Dk*M*N*Df*Df가 될 것이다
depth-wise separable convolution은 이 연산량을 줄이기 위한 방법으로
총 depthwise convolution과 pointwise convolution 총 두단계로 나누어 진행되어 집니다
depthwise convolution은
Df*Df*M의 input에 대하여 Dk*Dk*1의 컨볼루션을 N개 대입하여 총 Df*Df*M차원의 output이 나올 것이며
해당 연산량은 Dk*Dk*1*M*Df*Df가 될 것입니다

이후 potinwise convolution에서는 Df*Df*M차원의 input을 받아
1*1*M 의 filter를 N개 사용하여 원하는 차원의 출력을 맞춰주는 과정으로
결과는 Dk*Dk*N차원이 될 것이며 해당 출력은 기존 convolution을 진행한 것과 동일합니다
pointwise convolution의 총 연산량은 1*1*M*N*Df*Df 가 될 것입니다
depthwise separable convolution의 총 연산량의 앞의 두 연산량의 합인
(Dk*Dk*1*M*Df*Df)+(1*1*M*N*Df*Df )가 될 것이며
기존 convolution 과정의 연산량인 Dk*Dk*M*N*Df*Df와 비교해 본다면
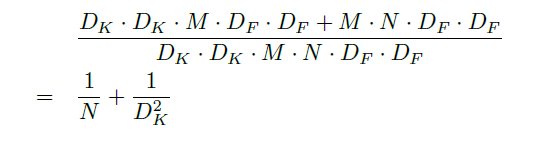
해당 수치만큼의 연산의 감소가 이루어질 것입니다


해당 논문의 전체 구성입니다
좌측 이미지의 왼쪽 부분이 기존의 convolution이며 3*3 convolution을 이용한 뒤 Batch Nomalization을 진행하였고
좌측 이미지의 우측 부분이 depthwise separable convolution 을 사용한 해당 논문의 구성입니다
우측 이미지의 경우 모델의 전체 구성입니다
Downsampling을 위해서 stride 2 를 사용하였으며
총 28 convolution layer로 구성되고
마지막 average pooling 이후 Fc layer와 연결하는 것을 확인할 수 있었습니다
실제로 연산량을 감소시키기 위하여 Mobilenet의 대부분의 연산(95%)는 1*1 convolution 연산이며
모델의 파라미터 또한 (75%)가량이 1*1 convolution 파라미터 입니다
그만큼 효과적으로 모델의 연산을 줄인다는 의미이며
small network일 수록 overfitting 문제가 일어나지 않는다는 점을 고려하여
따로 data augmentation은 사용하지 않았습니다
2개의 하이퍼 파라미터 width multiplier과 resolution multiplier를 사용하며
width는 채널수 resolution은 해상도를 감소시킵니다
width multiplier은 α값으로 나타내어지며 resolution multiplier은 ρ로 표시됩니다
해당 파라미터들은 0< α,ρ <=1의 값을 가지며
해당 파리미터들을 적용한 전체 연산량은
DK · DK · αM · ρDF · ρDF + αM · αN · ρDF · ρDF 다음과 같습니다

다음은 해당 모델의 결과분석표 입니다
table4를 보면 상단이 depthwise separable convolution을 미적용한 상황이며 하단이 적용한 상황으로
정확도는 1% 감소하였지만 연산량과 파라미터의 수를 약 1/9수준으로 줄여주는 모습을 볼 수 있습니다
해당 모델은 거의 3*3 convolution filter을 사용하였고 Dk=3을 위의 연산량 감소 수식에 대입하면
해당 결과와 비슷한 수치의 값을 확인 할 수 있습니다
table5를 보면 depthwise separable convolution를 사용하고 α=0.75를 적용한 모델과
α를 적용하지 않고 비슷한 연산량과 파라미터 수를 맞추기 위하여 layer를 대폭 줄인 모델과 비교한 결과표 입니다
해당 결과로 α 값을 적용한 상황이 연산량은 약간 증가하지만 정확도 측면에서 3%의 차이로 효율적인 모습을 보여줍니다
table6에서는 α의 수치를 줄여감으로써 정확도와 연산수를 확인하는데
α = 0.25 사용시 정확도 부분에서 떨어지는 모습을 보여 주었습니다
table7 에서는 ρ사용에 대한 정확도와 연산수 파라미터를 비교합니다
ρ역시 적당 수치를 사용하면 매우 효과적임을 볼 수 있습니다

해당 결과를 포함한 이후 내용에서는 타 모델과 Mobilenet을 비교합니다
결과를 확인하면 연산량 파라미터와 정확도 측면에서 매우 효율적임을 볼 수 있으며
해당 방식을 face , object detection등 여러 분야에서 사용하여
model 경량화에 매우 효율적인 모습을 보여 주었습니다
'논문리뷰' 카테고리의 다른 글
| DSSD:Deconvolutional Single Shot Detector (0) | 2022.03.17 |
|---|---|
| SSD: Single Shot MultiBox Detector 논문리뷰 (0) | 2021.12.15 |
| GoogLeNet (inceptionet) 논문리뷰 (0) | 2021.12.08 |
| You Only Look Once(YOLO) v1 논문 리뷰 (0) | 2021.12.01 |
| Resnet 논문리뷰 (0) | 2021.11.23 |


