Spatial Pyramid Pooling
SPP-net이라고 불리는 논문에 대하여 리뷰해 보겠습니다
해당 논문은 이전 이미지 분석을 위해 이미지를 convolution layer에 넣고 feature map을 만든뒤
FC-Layer로 통한 분석을 진행하는 과정에서 특정 수의 FC-Layer의 node 수를 위해
입력 이미지의 크기를 고정시키지만 이미지를 고정시키지 않기 위해 고안된 기법입니다
고정 이미지의 이유로는 FC-Layer에서 고정된 크기가 필요하며 이를 해결하기 위하여
다양한 convolution layer에서 feature map을 뽑아내고 해당 feature map을
FC-Layer 직전 고정 크기로 변환시키는데 목적을 둔 기법입니다

|


다양한 크기의 이미지를 입력으로 받아
convolution layer을 거치고 convolution layer의 결과인 feature map을
각 size의 grid cell로 분리를 진행합니다
해당 사진에서는 총 4*4 , 2*2 ,1*1 로 grid를 진행하는 모습이며
각 grid cell로 변환하는 과정에서는 max-pooling을 사용합니다
이후 해당 grid cell의 결과들을 결합하여 FC-Layer에 맞는 크기의 벡터로 만드는 과정입니다
해당 사진의 경우 총 3개의 grid cell(4*4 , 2*2 ,1*1)로 진행하며
해당 사진의 경우 총 채널수 * (16+4+1) 차원 벡터가 생성됩니다
이후 결합한 백터를 FC-Layer의 input으로 사용하며
FC-Layer 이후 SVM을 거쳐 Classication을 진행합니다
결과 분석입니다
학습에 대한 결과는 ZFNet / ConvNet / Overfeat 모델에 각각 SPP layer를 적용해 학습을 진행하였습니다
학습 자체는
Level
single-level : 피라미드 하나
multi-level : 6*6 / 3*3 / 2*2 / 1*1
: 4*4 / 3*3 / 2*2 / 1*1 Size
Size
single-size : 입력 이미지 크기가 하나
multi-size : 224*224 / 180*180 두 가지로 진행
: epoch마다 size 바꿔가며 train
으로 진행하였으며
학습 결과로는 single-level과 multi-level의 차이는 확연하게 나타났으나
multi-level의 size에 대한 차이는 거의 없는 것으로 확인되었습니다

다양한 모델에 적용한 결과입니다
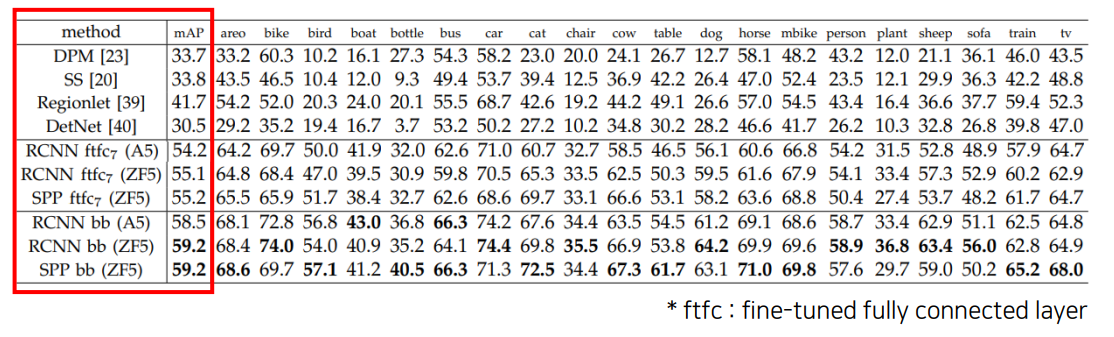
SPP-Net을 적용한 모델이 타 모델에 비해 높은 정확도를 보여주는 것을 확인 할 수 있습니다
다만
여러 단계의 학습 필수 : end-to-end 학습 불가
최종 classifier인 binary SVM, Region Proposal은 여전히 selective search 사용
Fine-tuning 시, SPP 이전의 Conv layer 학습 불가 (FC layer만 학습 가능)
이 있습니다