이번에 리뷰할 논문은 VGG16 논문입니다
해당 논문은 Convolution layer depth가 정확도에 끼치는 영향을 다룬 논문이며
layer depth를 늘리는 방법으로는 기존 7*7 11*11등으로 큰 크기의 convolution filter 들을
3*3필터를 여러번 사용하는 것으로 진행하여 layer depth를 늘렸습니다
해당 논문의 결과로 2014 ImageNet 대회에서 localization 1등 classification 2등의 성적을 거두며
다른 Data set에도 높은 정확률을 보여줍니다
기존 CNN의 발전은 대규모 Data의 확보,GPU의 발전등으로 성능을 증진시켰으나
증진 정도가 미미하였고
해당 논문에서는 depth를 늘림으로써 성능을 향상시키는 방법에 대하여 연구를 진행하였고
앞서 말한 것 처럼 large size filter 대신 3*3 filter를 여러개 사용함으로써 depth를 늘려 주었습니다
2.1
input image는 224*224*3(RGB)를 넣어 주었으며
전처리로는 각 픽셀에 전체 RGB의 평균을 빼는 작업을 진행하여 전체 이미지의 RGB 평균값을 0으로 맞추는 작업을 진행하며
Conv layer 에서는 3*3 과 1*1 filter 을 사용합니다
stride는 전부 1을 사용하며 3*3 filter 사용시 padding 을 1을 줍니다
5개의 max pooling layer 을 사용하며 max pooling은 (2*2를 사용하고 stride 는 2를 사용합니다)
FC계층의 layer은 총 3개를 사용하며 각각의 채널은 4096,4096,1000 입니다
마지막 계층은 1000개의 분류를 진행하는 softmax 계층으로 구성됩니다
모든 은닉층의 활성 함수는 ReLu 사용 LRN(local response nomalisation)은 계산 시간 및 메모리 문제로 사용하지 않습니다
2.2

해당 표를 참고하면 A~E는 구조는 앞과 동일하지만 총 depth만 11~19로 차이를 준 모델입니다
처음 64개의 채널에서 총 512 채널을 만들기 위하여 width를 2배씩 늘렸습니다
아래의 table 2를 참고하면 깊이는 늘어났지만 파라미터의 개수는 상대적으로 차이가 나지 않음을 볼 수 있고
깊이를 늘리는 기술은 앞서 말한 것 처럼 하나의 큰 필터를 3*3 여러개의 결합으로 나타내는 것 인데
(N*N) Matrix에 (M,M)의 필터로 Padding =Y stride=X 로컨볼루션을 적용하면
결과는 (N-M+2Y)/X + 1 이 된다 해당 방법으로 계산시
5*5 filter은 3*3 filter 2개를 사용한 결과와 같으며
7*7 filter은 3*3 filter 3개를 사용한 결과와 같습니다
큰 filter를 사용하는 것 보다 3*3filter 를 여러개 사용할 시의 이점은
decision function이 좀더 명확하게 판단이 가능하며
우리가 7*7 의 K차원 필터를 사용할 시는 7*7*K = 49K의 파라미터가 필요하지만
3*3 K차원 필터를 3개 사용할 시는 3*3*3*K = 27K로 파라미터의 개수 또한 줄어듭니다
3.1
Traing 측면에서는
기본적인 training은 Alexnet이 기반이며
Minibatch 방식을 사용하고 batch size 256 momentum 0.9
역전파 알고리즘을 사용 하였으며 처음 2개의 FC layer에 dropout 0.5를 적용하였습니다
처음 learning rate 은 0.01을 사용하였으며
10개의 검증 정확도가 변하지 않으면 learning rate을 1/10으로 줄입니다
현재 모델에서는 3번의 learning rate의 변화가 존재하였으며
사전 초기화 작업과 정규화 작업을 포함하여 총 370000회 학습하였습니다(74epochs)
deep network에서 초기 가중치 설정은 매우 중요하며
random initialisation이 가능한 A로 학습 시작하였으며
Convolution 4개 FC 3개 층을 A로 초기화(평균:0 분산:0.01)하고
단 학습동안 pre-initialized 층의 learn rate를 줄이지 않았습니다
input image에 대하여는
resize , flip , random RGB colour shift를 사용하였으며
224*224 이미지로 input 짧은 부분이 있으면 224로 맞춘후 random하게 crop해 주며
Training image scale : S
S값 설정에는 두가지 방법이 존재(S는 training scale)
Single-scale training –S를 256또는 384로 고정하였고
S값을 384로 설정시 기존 256으로 pre-training후 S를 384로 다시 training합니다
Multi-scale training-S를 256~512중 하나의 값으로 설정하며(scale jittering)
이미지들이 같은 크기가 이니기 때문에 해당 방법시 효과가 증가되었고
속도상의 이유로 S=384인 Single-scale로 fine-tuning 합니다
3.2
Test image scale : Q
S(training data scale) 하나당 Q(test data scale)가 있는경우 더 좋은 효과를 가지며
FC layer들을 Convolution layer로 바꾸어 test(첫번째 fc 7*7 나머지 1*1)
마지막 채널수 = 분류 class 개수 test set도 수평 반사시켜 사용합니다
모든 size의 test input image 사용 가능하며
input에 따라 다른 크기의 output = class score map
Size에 따라 값을 평균내서 사용합니다 (sum-pooled)
결과적으로 원본과 반사된 사진들의 softmax 평균을 구하여 최종결과를 산출하며
Test과정에서 multi-crop을 사용하는것은 정확도가 향상되기는 하나
정확도 비례 계산 횟수가 너무 증가하여 비효율적입니다

3.3
Multi GPU
병렬로 처리되는 여러 GPU의 batch에서 각 training image들을 분할하여 사용하며
각 GPU의 계산이 끝난후 full batch 값을 알기 위해 평균 계산을 진행합니다
Gradient의 계산은 모든 GPU에서 이루어짐 다중 GPU와 단일 GPU의 계산값 동일하였고
4-GPU 시스템은 단일 시스템보다 약 3.75배 속도 향상을 확인할 수 있습니다
4.1

Training(1.3M) Val(50K) Test(100K)의 Data set
Top 1 / Top 5로 평가하고
SINGLE SCALE EVALUATION
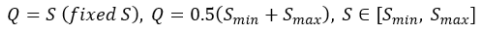
다음 식에 기반하여 Q 와 S 설정하였고
LRN(Local Response normalization)
사용시 성능은 차이 거의 없습니다
같은 깊이이지만 1*1 필터 3개를 사용한 C보다
3*3 한 개를 사용한 D가 높은 성능을 보여주고
고정된 S 보다 S∈[S_min(256), S_max(512)]
가 더 좋은 성능을 보여줍니다
4.2

MULTI-SCALE EVALUATION
Train 과 Test 의 크기 차이가 많이 날 경우 성능이 저하되기 때문에
Q = {S-32, S , S+32} – S 고정시
Q = {S_min, 0.5(S_min + S_max), S_max} - S∈[S_min; S_max]
결과를 확인하면 D와 E의 scale jittering(S값 유동적)
이 가장 좋은 결과를 가집니다
4.3

Multi crop 방식과 Dense evaluation 의 softmax outpu를 평균내서 비교하면
Multi crop 방식이 Dense evaluation 보다 좋은 성능 보이나
Multi crop 과 Dense evaluation 방식을 섞어 사용하는 것이 최고의 성능을 보여줍니다
4.5

여러 모델들의 softmax한 후 값의 평균을 수치화 한 표를 참조하면
모델들의 상호 보완성 때문에 성능이 개선되었고
가장 좋은 성능은 D와 E 모델에 Multi crop과 dense eval 방식을 합한 것이
가장 좋은 성능을 보여줍니다
4.6

표를 참조하면 GoogLeNet보다 VGG의 성능이
우수함을 알 수 있으며
해당 연구를 통하여
네트워크의 깊이를 늘림으로 인하여
성능의 증가를 이끌어낼 수 있다는
결과를 도출합니다
'논문리뷰' 카테고리의 다른 글
| Resnet 논문리뷰 (0) | 2021.11.23 |
|---|---|
| Faster RCNN 논문리뷰 (0) | 2021.11.16 |
| Fast R CNN 논문리뷰 (0) | 2021.11.08 |
| Rich feature hierarchiesfor accurate object detectionandsemantic segmentation(RCNN)논문요약 (0) | 2021.10.26 |
| Alexnet 논문리뷰(ImageNet Classification with Deep Convolutional) (0) | 2021.10.05 |



