Fast RCNN이란
이전과 같이 region based deep convolution network 이며
이전 RCNN과 SPPnet(추후 리뷰)비례 훌씬 빠른 속도와 정확도(RCNN대비 train 9,test 213/SPPnet train 3,test 10)
를 가진 모델입니다
기존 모델의 문제점은 후보군 설정과 정확한 후보군 설정을 위한 처리 과정에서 Complexity가 존재했었는데
Fast RCNN은 Single stage training algorithm(후보군 설정과 처리를 한번에 진행)으로써
Better Performance – 0.3s(each image) , mAP=66% 을 보여줍니다
1.1
기존 RCNN & SPPnet은
Log loss(loss function for classification)을 이용하여 fine tune하며
각 featur들로 SVM
Bounding box regressor 들을 학습합니다
Training is expensive
각 이미지의 region proposal 마다 feature들이 계산되 많은 시간과 디스크 용량이 소요되고
Gpu 로 학습 진행시 각 이미지마다 47s의 학습시간을 가집니다
각 proposal 들의 연산이 공유되지 않음으로 느림(개선시킨것이 SPPnet)
Sppnet은 feature map 계산후 공유 해당 feature로 분류
Max pooling을 이용하여 6*6을 출력(spatial pyramid pooling)
하지만 너무 많은 단계의 pipeline이 필요하며
Very deep network에 부적합하다는 단점이 존재합니다
1.2
Fast RCNN의 특징으로는
-R-CNN 이나 SPPnet 보다 높은 mAP
-single stage traing(region proposal+classfication)
- multi task loss(classification+bounding box)
-Training can update all network
-no disk storage(for feature caching) 이 있습니다
2

위의 Fast RCNN의 구조를 참고하면
– input = image & proposals
-image 를 cnn구조 통과 그 후 feature map 구성되고
-각 proposal 마다 Roi pooling layer 에서 featual vector 추출하며
-각 featual 을 FC layer 에 통과시켜 bounding box를 위한 4개의 수치및 class분류 값이 생성됩니다
2.1
RoI pooling layer
-Roi pooling방식은 max pooling의 일종이며 유효 범위의 featual map을 만드는 방법이며
입력값으로는 H,W- hyper parameter
(r,c,h,w) –r,c = 왼쪽 위 모서리 위치 - h,w 높이,길이 (유효범위 featual map)
(r,c,h,w)로 추출된 featual map 에 (h,H),(w,W)크기로 grid
각 부분을 max pooling하여 grid 한 부분마다 하나의 값을 추출합니다
Sppnet 에서 사용한 pyramid pooling을 간단화 한 방식이라 생각하면 될 듯 합니다
2.2
해당 연구는 3개의 pre-trained ImageNet networks로 진행되며
5개의 pooling layer 와 5~13개의 convolution layer 로 구성됩니다
Fast RCNN의 사용에 용이하게 3가지를 변형하였으며
Last max pooling layer = Roi pooling layer(first FC layer 와 H,W 가 호환되게 설정)
Last FC layer 과 softmax가 K+1개의 object softmax와 box regressors로 바뀝니다
여기서 +1인 이유는 출력으로 background까지 출력하기 때문입니다
Input = image + image’s Roi proposal 이 주요 변경 내용입니다
2.3
SPPnet은 back-propagation 방식을 사용할시 매우 비효율적입니다
SPPnet의 구성을 보면 CNN + SVM으로 이루어져 있는데
각각 다른 네트워크로 생각해야 하기 때문에 비 선형성을 가지기 때문에 효율성이 떨어지는데
Fast RCNN은 SVM대신 Softmax방식을 사용하며 처음부터 끝까지 한개의 네트워크로 해결되는
end-to-end 네트워크 구성이기 때문에 선형성을 가져 앞의 알고리즘에 비해 효율성이 높습니다
또한 fine-tuning에 걸리는 시간 자체도
RCNN 과 SPPnet 같은 경우는 CNN 과 SVM 각각을 조정해야 하지만
Fast RCNN방식은 CNN만 조정하면 되므로 속도 또한 빠른 결과를 보입니다
Fast RCNN 방식은 Mini batch 형식을 사용했으며
N 과 R로 나누어지며 N 은 한번에 진행할 image 의 수 R은 총 Roi의 개수이고
총 N개의 image에서 각 R/N개의 Roi를 샘플링하고
각기 다른 R개의 이미지에서 1개의 Roi개를 추출하는 것 보다 R/N배 빠릅니다
Fast RCNN같은 경우는 시작부터 끝까지 한개의 네트워크로 이루어진 end-to-end network
이므로 conv + SVM 으로 이루어진 SPPnet에 비해 fine tuning이 효율적입니다
Fast RCNN은 2개의 출력층 존재-classification category , bounding box regression
Classification 에는 softmax 사용했으며 (FC layer)
p=output(softmax),u=ground-truth class,
t^u bounding box regression,v=ground-truth box target
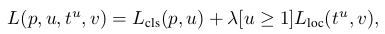
Lcls(p, u) = − log p ---> classification loss
Lloc(t u , v) = X i∈{x,y,w,h} smoothL1 (t u i − vi) --> regression loss 이며
L1(절대값형식) 이 L2(제곱)에 비해 덜 민감함으로 L1사용되고 v는 평균 0 표준편차 1
λ 는 앞의 2개의 loss의 균형을 맞춰주는 의미이며 해당 방법에서는 1로 사용됩니다
Fine tuning 시 각 SGD batch는 N=2, R=128
각 image 당 64 개의 Roi가 생성되고
그 이후 IOU >= 0.5이상의 Roi 들중 25%는 foreground object class로 라벨링(u>=1)
Ground truth와 IOU가 0.1~0.5 범위는 배경으로 라벨링(u=0)되며
0.5의 확률로 flip을 이용한 data augmentation 사용됩니다(이 외의 data augmentation은 미사용)
Softmax 와 bounding box 를 위해 사용된 FC layer – 평균=0 표준편차 =0.01,0.001
Bias = 0, 가중치의 pre-training learning rate =1 bias = 2
Global learning rate = 0.001
VOC07,VOC12학습시 SGD(Mini batch)로 30k번 실행되고
이후 learning rate 0.0001로 10k 추가 진행됩니다
2.4
출력을 일정하게 맞추기 위해 2가지 방법을 고안하였습니다
brute force & multi-scale approach
Brute force- image의 training , test시 정해진 픽셀 사이즈로 고정
multi-scale approach –image pyramid 사용 GPU의 한계로 작은 크기의 네트워크에서만 진행하였습니다
3
Fine tuning 이후 네트워크는 input으로 image와 R개의 proposal을 받음(거의 2000)
SVD 기술은 특이값 분해를 뜻하며
즉 u*v로 이루어진 하나의 matrix W가 있으면
해당 매트릭스는 u*t matrix 인 U t*t대각행렬인 Σt v*t matrix V로 나타낼 수 있습니다
해당 방법을 사용 시 기존 u*v개의 파라미터 개수에서 t(u+v)개로 감소한다는 이점을 가지며
t가 min(u,v)보다 작을 시 더 큰 이점을 가져옵니다
4
결과적으로는 VOC07/2010/2012의 최고 수준의 mAP
R-CNN과 SPPnet에 비해 빠른 학습 및 테스트 시간을 가지고
Convolution 층의 fine tuning으로 mAP 를 향상 시켰습니다
4.1

R-CNN으로부터 가져온 CaffeNet을 S
VGG_CNN_M_1024를 M
VGG16을 L로 설정
S, M, L은 모델의 크기에 따라 분류 여기서 크기란 채널의 수를 말하며
VGG16 으로 pre-training 되었으며
VOG 2010 의 결과를 비교해 보았을때 VOC 07 + 12 년도의 데이터 셋으로 테스트시 앞의 모델보다 높은 성능을 가지며
VOC12 대회에서 Fast RCNN은 최고의 결과를 산출되었고
VOC07 의 결과로 비교해 볼 경우에도 앞의 RCNN과 SPPnet비례 높은 성능을 보여줍니다
여기서 07++12 의 뜻은 07년도의 trainset과 testset 12년도의 trainset 전체를 모델의 trainset으로 사용했다는 것을 의미합니다


Train time 측면에서 확인 해 볼 때에도 다음과 같이 RCNN 과 SPPnet 비례 짧은 training time 을 가지며
mAP 측면에서도 뛰어난 성과를 거두었습니다
SVD를 사용시에는 mAP 측면에서는 아주 약간 낮아지는 경향을 보여주었으나
Detection time 측면에서는 30% 의 성능 향상을 보여 주었습니다
Fine tuning 측면에서는 SPPnet은 FC 계층에서만 진행되었으며
Very deep netsork에서는 conv layer도 fine tuning 해 주는것이 더 높은 성능을 보여주었으며
특히 conv 3_1 layer 부터 fine tuning하는 것이 가장 효율이 높았습니다


위의 좌측 표를 참고하면 multi-task-training + bounding box regressor을 사용한 경우
mAP 가 좋은 성능을 가지는 것을 알 수 있으며
위의 우측 표를 참고하면 픽셀 사이즈를 고정시키는 방식보다 multi scale 방식이 대체적으로 좋은 것을 볼 수 있으나
L 방식에서는 GPU 메모리 상의 문제로 multi scale 방식을 사용하지 못하였습니다

또한 더 많은 dataset 이 주어진다면 더 높은 성능을 보여줌을 확인하였고
위의 표를 보면 softmax가 SVM보다 더 높은 성능을 보여줌을 확인 할 수 있습니다

마지막으로 위의 표를 참고하면 proposal을 계속 증가시킨다면 오히려 정확도가 낮아진다는 것을 확인 할 수 있습니다
'논문리뷰' 카테고리의 다른 글
| Resnet 논문리뷰 (0) | 2021.11.23 |
|---|---|
| Faster RCNN 논문리뷰 (0) | 2021.11.16 |
| VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE -SCALE IMAGE RECOGNITION(VGG16)논문리뷰 (0) | 2021.11.02 |
| Rich feature hierarchiesfor accurate object detectionandsemantic segmentation(RCNN)논문요약 (0) | 2021.10.26 |
| Alexnet 논문리뷰(ImageNet Classification with Deep Convolutional) (0) | 2021.10.05 |



