이번에 리뷰해볼 논문은 resnet 논문입니다
ResNet 논문은 이전 VGGnet의 결과인 깊이가 깊어질시 정확도가 상승한다 라는 결론에 대해
실제로 해당하는지 테스트 후 수정한 논문입니다
이전 VGGnet이 16/19개 layer을 사용하였다면 ResNet은 1202 layer까지 깊이를 상승시키며 테스트를 진행하였습니다

우선 해당 결과에 대해 주목해 볼 필요가 있습니다
해당 결과는 CIFAR-10 dataset을 가지고 VGGnet 20/56 layer에 대하여 테스트를 진행 해 본 결과표 인데
해당 결과를 보면 이전의 결론인 깊이가 깊어질수록 error rate는 낮아진다 가 아닌 오히려 더 증가하는 결과를
보여주고 있습니다
정확도가 일정 수준 포화되면 급격히 감소하는 추세를 보이며 깊은 모델에서 더 큰 error rate을 보여주었습니다
이를 degradation이라 하며 degradation은 overfitting에 의해 유발된 것이 아니고
깊은 구조에 의한 vanishing gradient, exploding gradient 역시 normalized initialization, intermediate normalization 로
해결이 되었다고 나오기 때문에 해당 이유 또한 아닙니다
해당 논문에서는 degradation이 일어나는 정확한 이유는 발견하지 못하였고 해당 증상에 대한 해결 방법만 다루고 있습니다
여기서 vanishing gradient는 깊이가 깊어짐에 따라 많은 가중치값들이 소실되어 feature map이 점점 의미를 잃어가는 현상을
말하며 exploding gradient는 learning rate가 커짐에 따라 가중치값이 수렴하지 않고 발산하는 형태를 말합니다
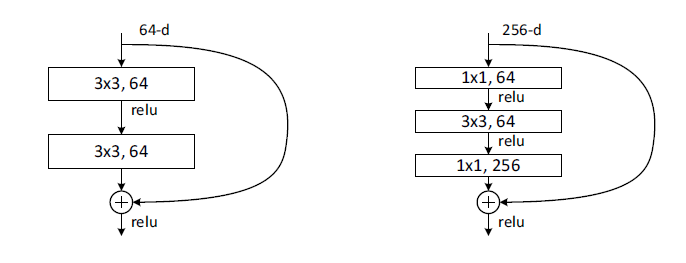
degradation을 해결하기 위하여 나온 방법이 deep residual learning framework입니다
쉽게 설명하면 input x에 대하여 input에 대한 실제 정답값과 예측값의 차이인 residual을 학습하는 것입니다

H(x) 는 input에 대해 공식화 시켜 mapping한 값이며
F(x) := H(x)−x F(x)는 예측값과 실제값의 차이 라고 생각하면 될 듯 합니다
F(x)+x 은 shortcut을 이용하고 수렴에 있어 최적화를 위해서 위의 식을 이항시켜 구한 식입니다
여기서 shortcut이란 기존의 input값을 n개의 layer을 건너뛰어 연산에 사용하는 방식을 말합니다
해당 방법을 사용했을시 최적화에 이점을 가지며
추가적인 파라미터나 연산이 필요하지 않으며
이전과 동일하게 back propagation을 이용한 SGD로 end-to-end 연산이 가능합니다


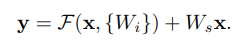
위 3개의 식은 F(x)+x을 자세히 설명한 식이며
x=input y=output
위의 두번째 식은 2개의 layer가 존재하는 경우이며
Bias는 이해를 돕기 위하여 생략합니다
F + x 는 shortcut connection 나 element-wise addition 로 진행
Ws는 입력과 출력단의 차원을 맞추기 위하여 사용하며
parameters, depth, width등을 전부 맞추어 주어야 하고
1개의 layer에 대해서도 사용이 가능하나 큰 의미가 없습니다
ImageNet dataset 뿐만이 아닌 CIFAR-10 dataset으로도 테스트를 진행했는데
이는 degradation이 ImageNet dataset 에 국한되지 않고 전 dataset에서 발생한다는 것을 의미하며
해당 dataset을 사용하여 총 1202 layer까지 실험을 진행하였습니다
깊이가 훨씬 깊어졌음에도 불구하고 VGGnet보다 복잡도가 낮아졌으며
Ensemble 의 error rate값은 3.57%를 달성하며 이는 사람의 판단보다 더 뛰어난 판단을 하는 수준입니다

Plain network = VGG net 기반
feature map size가 절반 인 경우,
layer 당의 time complexity를 보전하기 위해 filter의 수를 2배로 하며
FC Layer output = softmax
Global average pooling
VGG-19에 비해 적은 수의 filter로 낮은 complexity
3.6 billion FLOPs , VGG 19(19.6%)의 18%
기존 VGGnet과 Plain 모델의 연산량이 차이나는 가장 큰 이유는 FC Layer에 있습니다
convolution 연산의 경우 학습 되어져야 하는 gradient의 개수는
위의 방식처럼 3*3 filter 64개 사용시
학습은 필터 각각의 gradient를 학습시키는 것이기 때문에 3*3*4 개가 되며
각각의 layer들의 gradient는 덧셈 연산으로 들어가지만
FC Layer의 경우 곱셈 연산으로 들어가며
4096 4096 1000 이 3개의 FC Layer의 경우
4096*4096*1000 개의 gradient를 학습시켜야 하기에 연산량에서 큰 차이를 보여주는 것입니다
따라서 resnet에서는 연산량을 줄이가 위하여 FC Layer 대신 Global average pooling을 사용하였기 때문에
연산량이 적습니다
Residual network
Identity shortcut 은 input output이 동일한 경우=실선
Input output의 차원이 다른경우 = 점선
점선인 경우
Zero entry 를 padding 하여 dimension matching 후 진행 - identify shortcut
Projection shortcut 하여 dimension matching 후 진행
projection shortcut - 1*1 convloution 이용하여 차원 맞춰주는 방식
왼쪽은 VGG-19 model (19.6 billion FLOPs)
가운데 34-layer plain network (3.6billion FLOPs)
우측 34-layer residual network (3.6 billion FLOPs) 을 가집니다
FLOPS는 연산량이라 보시면 될 듯 합니다
test에 사용된 모델의 architecture을 살펴보면
Image [256,480]에서 random하게 샘플링 된 input을 사용
224*224로 crop , horizontal flip 사용 , standard color augmentation 사용
Batch normalization = 256 사용
Weights initialize 사용
Learning rate 0.1 시작 특정 기점시 10으로 divided
0.9 momentum dropout 방식을 사용하지 않았습니다
1000개의 class로 구성 된 ImageNet 2012 dataset 으로 제안하였으며
학습 및 테스트 1.28M/50K/100K Train/Val/Test
Plain network
18/34 layer 구성 18layer에 비해 34layer의 error이 높게 나타남
Vanishing gradien는 없는 것으로 추정됨
(batch nomalization 방식으로 학습하여 Forward propagation의 분산이 0이 아님)
Residual Network
18 layer 및 34 layer 을 평가
Base model은 plain과 동일하며
Dimension matching 을 위해서는 zero padding 을 사용
3*3filter 에 shortcut connection사용
대응되는 plain에 비해 추가 parameter (x)
결과적으로
ResNet 은 plain에 비해 수렴이 빠르며 더 높은 정확도를 가지며
Depth가 늘어날수록 좋은 정확도를 보여줍니다
18 layer의 plain모데로가 residual 모델을 비교해 보면 정확도가 거의 같은 것을 볼 수 있지만 실제로는
훨씬 빠른 수렴 속도를 보여주었습니다


앞서 shortcut을 진행할 시 연산 진행할 시 차원을 맞춰주어야 하는데
앞에서 소개한대로
Identity shortcut = 원상태 그대로차원을 맞춘 후 입력값을 그대로 더해줌
Projection shortcut = 1*1 convolution을 사용하여 차원을 맞춰주는 방식이 존재한다
이들의 영향을 검증하고 어떤 방식을 택할지 결정하기 위해
(A) zero-padding shortcut는 dimension matching에 사용되며, 모든 shortcut는 parameter-free 하다
(B) projection shortcut는 dimension을 늘릴 때만 사용되며, 다른 shortcut은 모두 identity다.
(C) 모든 shortcut은 projection 이다
로 나누어 테스트를 진행하며

해당 결과를 보면 C>B>A순으로 성능이 좋지만 미미한 수준이며 time complexity와 model size를 줄이기 위하여
C방법은 사용하지 않는다
해당 논문에서는 bottleneck design이라는 방식 또한 설명하고 있는데
차원이 깊어짐에 따라 training time 에 대한 우려로 block를 bottleneck design으로 수정
2layer stack을 3layer stack로 수정하며
연산량을 최대한 유지하며 차원을 늘릴 수 있는 방법을 고안하였다
3*3 conv이전 1*1conv단에서 차원을 낮춘후 3*3conv이후 다시 1*1conv로 차원을
원래대로 수정
Depth는 깊어지나 time complexity는 비슷하고
Identity shortcut 사용되며 projection 사용시 model 복잡도와 size가 2배로 증가한다
해당 이유가 앞의 C방법을 사용하지 않는 이유이다
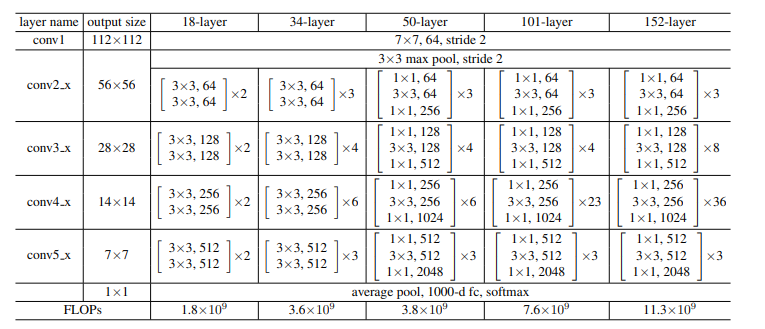
앞서 34 layer 까지 구성했다면 이제는 50/101/152 layer을 구성한다50 layer resnet = 34 layer resnet 2 layer block들을 3 layer block로 대체하여 구성한다
차원을 맞추기 위하여 B방법 사용한다
3.8 billion FLOPs
101/152 layer resnet = 3 layer block 사용 depth의 증가에 따라 정확도 또한 증가하며
152 layer ResNet model 같은 경우 11.3 billion FLOPs 로 VGG 16/19(15.3/19.6 billion)에 비해 낮은 연산량을 보인다
Degradation problem이 보이지 않는다

앞서 말한 방식으로 test를 진행시 layer가 깊어짐에 따라정확도가 높아진 모습을 볼 수 있다
Baseline 인 34 layer ResNet은 이전 SOTA 와 비슷한 정확도를 보여주며
152 layer 의 single-model top-5 error은 4.49%를 달성하였다
이는 이전의 ensemble 결과를 뛰어넘는 성능을 보여주며
서로 다른 6개의 ResNet을 ensemble한 결과 top–5 = 3.57% 달성하였다
imageNet dataset 에 대한 결과이다


CIFAR-10 dataset으로 실험 진행시에도 ImageNet의 결과와 같이
기존 plain한 model은 depth가 높아질수록 error이 커지는 경향을 보였으며
이후 ResNet의 경우 이를 극복하는 모습을 보여 주었다
각각 {32, 16, 8}인 feature map에 각 size 마다 3x3 conv가 2n개 적용되고
6n개의 layer stack을 사용하며
Global average poolling & Softmax 총 6n +2 개의 layer로 구성되며
110 layer Resnet 학습시 초기 learning rate 0.1시 수렴에 영향을 끼쳐
0.01로 학습 후 0.1로 바꾸어 학습한다
총 20,56,110,1202 layer까지 실험을 진행하였다


주의할 점은 1202 layer의 model의 결과를 살펴보면 110 layer 보다 높은 error rate를 보여주는데
이는 CIFAR-10은 소규모 dataset인데 반해 1202는 너무 큰 model이라 그런 것으로
생각된다
또한 maxout 또는 dropout등의 방식 또한 적용되지 않아 낮은 정확도가 나왔을 것이라
예상되며 위와 같은 방식 적용시 더 높은 정확도를 기록할 것이라 생각된다

'논문리뷰' 카테고리의 다른 글
| GoogLeNet (inceptionet) 논문리뷰 (0) | 2021.12.08 |
|---|---|
| You Only Look Once(YOLO) v1 논문 리뷰 (0) | 2021.12.01 |
| Faster RCNN 논문리뷰 (0) | 2021.11.16 |
| Fast R CNN 논문리뷰 (0) | 2021.11.08 |
| VERY DEEP CONVOLUTIONAL NETWORKSFOR LARGE -SCALE IMAGE RECOGNITION(VGG16)논문리뷰 (0) | 2021.11.02 |



